#001 独立开发者的文档驱动 AI 编程实践
我是 tyk,在美国 Yelp 做了六年程序员,三年前开坑了一款以航海为主题的模拟经营独立游戏。去年八月深感兼职开发效率过低,并且看着 AI 工具在眼前指数级飞速发展,于是觉得时不我待,裸辞回国开始了全职开发之旅。
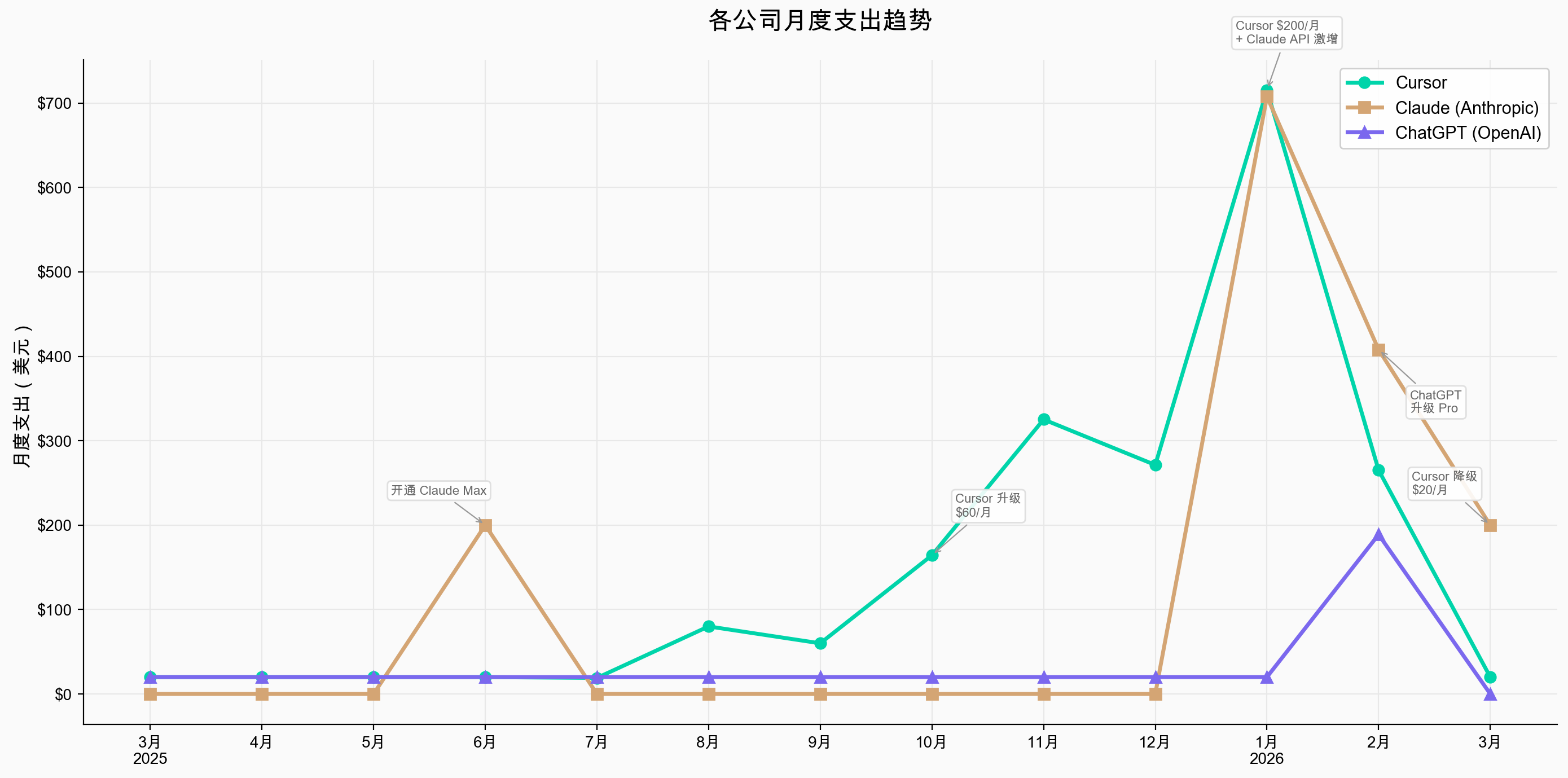
回国之后,AI 编程工具基本就成了我的主力员工。从 2025 年 3 月至今,我在 AI 编程工具上累计投入接近 4000 美金(约两万八千元人民币),在这个过程中踩了不少坑,也逐渐摸索出了一套相对稳定的工作流。虽然我在一个三人团队里工作,但我们各自负责的模块比较正交,所以我日常的开发状态基本是单兵作战——下面分享的工作流也是在这个背景下验证的。
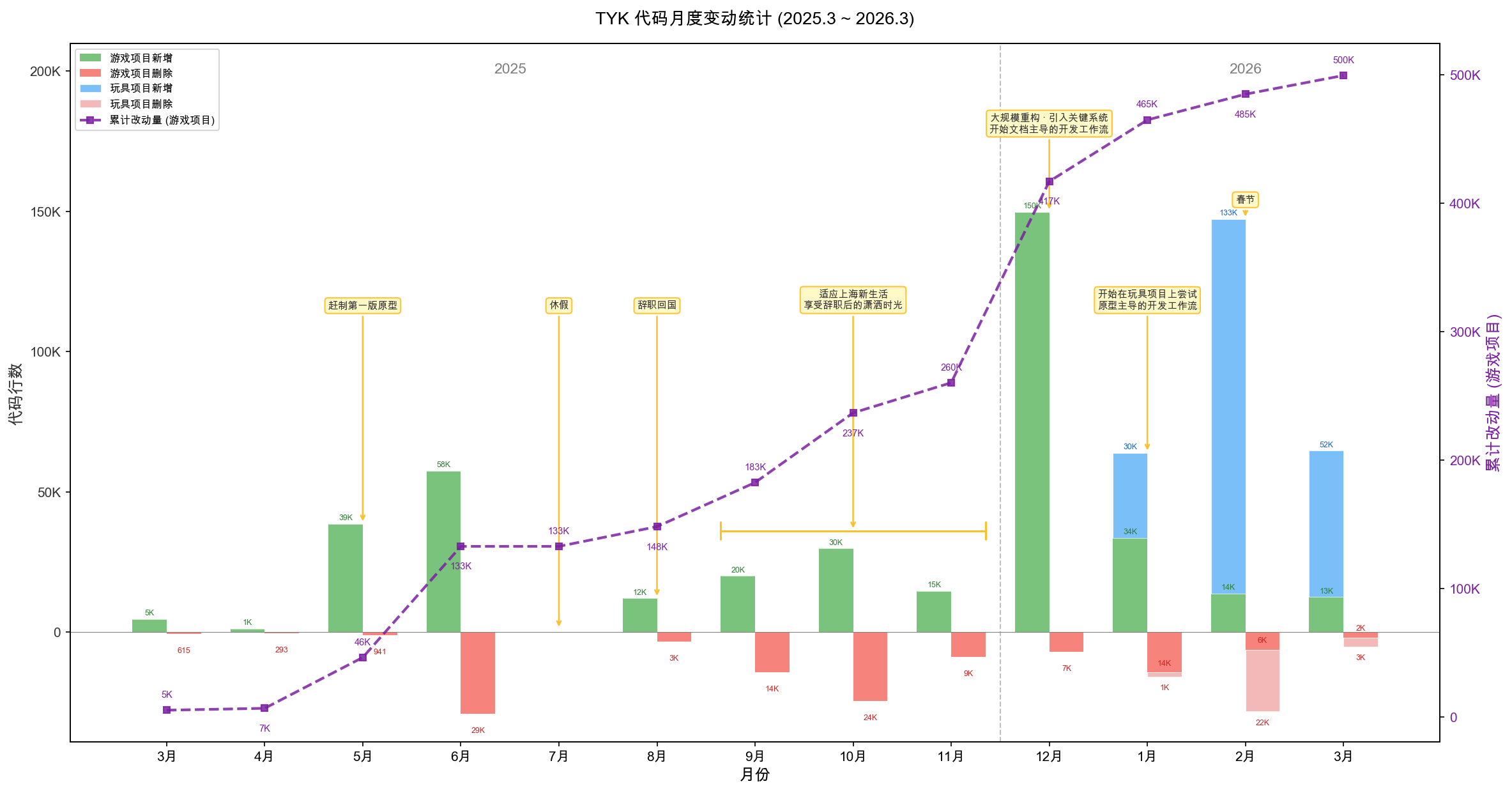 过去一年的代码月度变动统计(绿色为游戏项目新增,蓝色为实验项目新增)
过去一年的代码月度变动统计(绿色为游戏项目新增,蓝色为实验项目新增)
本文大致分为三个部分:
- 我的两种工作流 – 实际操作层面的流程分享
- 为什么我认为文档是核心 – 对当下 AI 编程范式的一些思考
- 踩坑总结和建议 – 零散但实用的经验
另外,我目前主要使用 Claude Code 和 Codex,所以下文中描述的具体操作都基于这两个工具,但我相信相关的流程和理念是可迁移的。
第一部分:我的工作流
我当前有两种主要工作流,针对不同类型的任务:
- 文档主导的工作流,针对体量大且方向相对明确的功能
- 原型主导的工作流,针对需求和方向非常不明确、或体量较小的功能
先来分享第一种。
工作流一:文档主导
在这个流程中,文档是第一公民。整个工作流都围绕文档构建,下面分阶段说明。
flowchart LR
P1[阶段一<br/>发散需求]:::ai --> P2[阶段二<br/>写PRD]:::human
P2 --> P3[阶段三<br/>Plan +<br/>Review]:::ai
P3 --> P4[阶段四<br/>实现]:::ai
P4 --> P5[阶段五<br/>测试 +<br/>迭代]:::review
P5 --> P6[阶段六<br/>人工Review]:::review
P6 --> PR[单元测试<br/>+ 开PR]:::done
P5 -.->|偏差?<br/>先改文档| P2
P6 -.->|不满意?<br/>回到PRD| P2
classDef human fill:#EF4444,color:#fff,stroke:none
classDef ai fill:#2563EB,color:#fff,stroke:none
classDef review fill:#F59E0B,color:#fff,stroke:none
classDef done fill:#10B981,color:#fff,stroke:none
阶段一:发散需求
假设你在开发一款主题公园模拟类游戏,已经写好了建筑放置系统、道路修建系统,接下来需要开发游客系统。
此时你脑中大概有一个模糊的方向:游客系统允许系统生成一些游客,让他们在道路上漫步,进入游乐设施并产生交互,从而带来收入变化、乐园评分变化、游客心情变化等。但更多具体细节还处于迷雾之中。
这时候就可以让 AI 帮你细化需求了。把零碎的、模糊的想法直接告诉 Claude,让它基于你的想法给出设计草案。可以显式地让它调研类似游戏,显式地让它提问和挑刺。此外一个重要的原则是:这个阶段不要让它写任何技术性内容,专注于逻辑本身。
一个我比较常用的 prompt 模板:
我在设计一个游客系统,[功能描述/功能描述草案],请你帮我
1. 调研类似游戏的系统
2. 扩充和细化功能
给我3个纯游戏逻辑设计方案,不要涉及技术内容,存到md里。
有不懂的可以问我。
如果觉得 AI 给的方案不够详细,还可以显式地让它开多个子 agent 进行深度调研,把调研文档写到不同的 markdown 文件里,然后自己阅读,看看能否带来额外的启发。
这一阶段的产出,可以类比为几个游戏策划开完头脑风暴会议后交上来的东西——相对发散,相对笼统。
下面这张截图就是根据上述需求,agent 产出的一个小章节样例。可以看到这些内容从玩家的视角来说已经相对具体了,但对于开发者来说,还不够具体到直接写代码:数值范围是多少、需求之间的转换关系如何、冲突时怎么处理、底层 AI 架构是什么样的——这些都还需要进一步细化。但作为这个阶段的产出,通常已经达标了。
 agent 产出的设计方案片段——从玩家视角已经相对具体,但对开发者来说还不够细化
agent 产出的设计方案片段——从玩家视角已经相对具体,但对开发者来说还不够细化
阶段二:写 PRD
这个阶段是我当前工作流里需要人工投入最多的,也是整个流程中最关键的一步。一般来说 50% 甚至更多的开发时间会耗在这里。这篇文档将成为你这个项目的核心资产。
在这个阶段,你需要人工阅读上一阶段的产出,和 agent 基于这个文档来回迭代、删改、优化,特别是细化,最终只保留你当前想要实现的内容。
这一步的产出,是一篇相对详细的软件行为描述文档,也就是常说的 PRD。
这里岔开说一句:PRD 的编写不存在一个可以生搬硬套的标准流程,因为软件类型、软件规模和开发团队的背景与偏好都会影响它的侧重点。我自己在公司内写过和读过的文档也是五花八门。
不过在我的工作流中,有几点是一定会包含在这篇文档中的:
1. 术语表。 一个系统要被规范化地、准确地描述,明确的术语定义必不可少。以游客系统为例:游客的”快乐值”到底是什么?它影响哪些其他系统?游客的决策会产生一组可叠加的状态还是单一行为?”游乐设施”包不包括商店?这些歧义如果不提前解决,AI 会按自己的理解来,等你发现时可能已经基于错误的理解写了好几百行代码了。
2. 交互方式。 用户如何与这个系统产生交互?游客是自动生成还是玩家手动召唤?玩家能不能控制单个游客?按什么键?如何控制?这部分定义了游戏最关键的玩家交互层。
3. 验收标准。 本质上是边界定义。在有限的时间范围内不可能无限优化和扩充一个系统,必须说明系统遇到边界情况时应当如何处理。写清楚验收标准的另一个好处是:这些自然语言描述的标准之后基本都可以转化成测试代码,避免后续频繁修改所导致的回归错误——这在编码速度急速增长的当下尤为重要。
附上一篇我们项目中实际使用并持续维护的 PRD 供参考:修建系统 PRD。我并不认为存在适用于一切项目的标准化格式,但希望能给大家一个思路。
阶段三:Plan + Review
到这个阶段,设计部分已经完成,进入实现环节。
我的工作流中,实现的第一步几乎永远是让 agent 基于前一步的文档做 plan。前一步产出的文档大多是软件行为描述文档,即使是技术文档,我一般也只会给出大致的技术栈和方向,必要时给一些个人偏好的 API 设计来限定边界,不会细化到指定修改哪个文件、实施步骤和示例代码这种层次。
当然,如果你对技术细节把控比较严格,在上一步已经有了一个非常细化并且经过你实践、agent 可以直接对着写代码的文档,这一阶段可以跳过。
在 Claude Code 产出了计划之后,我强烈建议 review 一下这个 plan,无论是人工还是让另一个 agent 来做。
实际操作中,我会用 Claude Code 的 plan 模式去 plan,然后让它调用 Codex 去 review,再让 Claude 根据 review 结果自己修复。一般 review 两轮左右,plan 就不会有什么致命问题了,最后自己扫一眼,没什么大问题就可以开始实现。
flowchart LR
CC["Claude Code<br/>制定 Plan"] --> CDX["Codex<br/>Review(+ 修复)"]
CDX --> FIX["Claude Code<br/>根据反馈修复"]
FIX -->|"重复 ~2 轮"| CDX
FIX --> HUMAN["人工<br/>最终确认"]
HUMAN --> IMPL["开始实现"]
style CC fill:#2563EB,color:#fff,stroke:none
style CDX fill:#10B981,color:#fff,stroke:none
style FIX fill:#2563EB,color:#fff,stroke:none
style HUMAN fill:#EF4444,color:#fff,stroke:none
style IMPL fill:#E5E7EB,color:#1F2937,stroke:none
另外,根据我的经验,显式地要求 agent 进行 TDD 可以有效提高开发效率,减少出错空间。这是我这个阶段常用的 prompt:
阅读[文档],帮我设计一个实现方案并且TDD
有不懂的可以问我
顺便解释一下为什么让 Claude Code 做 plan 而让 Codex review:过去一段时间我发现,Claude Code 像是那个善于沟通、对什么事情都充满经验、有全局观,但做事永远懒得做完、不太在意技术细节的、在公司待了五年的老油条;而 Codex 则像是刚毕业、满脑子造火箭的知识、非常专注细节、给一个方向能挖到底,但不太擅长非技术沟通也不太会写文档的应届生。所以我让它们各自负责各自擅长的领域。当然这可能因人而异,但多尝试不同的模型总归是有益的。
block-beta
columns 2
block:CC:1
columns 1
CC_TITLE["Claude Code"]
CC1["善于沟通,说人话"]
CC2["全局观,经验丰富"]
CC3["做事懒得做完"]
CC4["不太在意技术细节"]
CC5["→ 适合:Plan / 写文档"]
end
block:CDX:1
columns 1
CDX_TITLE["Codex"]
CDX1["专注技术细节"]
CDX2["给方向能挖到底"]
CDX3["不怎么懂沟通"]
CDX4["不怎么会写文档"]
CDX5["→ 适合:Review / 深度实现"]
end
style CC_TITLE fill:#60A5FA,color:#fff,stroke:none
style CC1 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
style CC2 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
style CC3 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
style CC4 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
style CC5 fill:#60A5FA,color:#fff,stroke:none
style CDX_TITLE fill:#34D399,color:#fff,stroke:none
style CDX1 fill:#ECFDF5,color:#065F46,stroke:#A7F3D0
style CDX2 fill:#ECFDF5,color:#065F46,stroke:#A7F3D0
style CDX3 fill:#ECFDF5,color:#065F46,stroke:#A7F3D0
style CDX4 fill:#ECFDF5,color:#065F46,stroke:#A7F3D0
style CDX5 fill:#34D399,color:#fff,stroke:none
阶段四:实现
到了实现这一步,如果想效率最大化,可以开一个新的 worktree 来做其他正交的功能。我一般会在做一个主要的大 feature 的同时,从这个 feature 分支开两个左右的 worktree 来做一些相对小的改动,这样可以最大限度降低人的空转时间。
flowchart TD
MAIN["main 分支"] --> FEAT["feature 分支<br/>大功能(Agent 实现中)"]
FEAT --> WT1["worktree 1<br/>小改动 A"]
FEAT --> WT2["worktree 2<br/>小改动 B"]
FEAT -->|"Agent 写代码<br/>你在等待"| WAIT["⏳"]
WAIT -.->|"切换到小任务<br/>降低空转"| WT1
WAIT -.->|"切换到小任务<br/>降低空转"| WT2
WT1 -->|"完成 ✓"| MERGE_WT["合并回 feature"]
WT2 -->|"完成 ✓"| MERGE_WT
FEAT -->|"大功能完成 ✓"| MERGE_WT
MERGE_WT --> MERGE_MAIN["合并回 main"]
style MAIN fill:#E5E7EB,color:#1F2937,stroke:none
style FEAT fill:#2563EB,color:#fff,stroke:none
style WT1 fill:#10B981,color:#fff,stroke:none
style WT2 fill:#10B981,color:#fff,stroke:none
style WAIT fill:#F59E0B,color:#fff,stroke:none
style MERGE_WT fill:#8B5CF6,color:#fff,stroke:none
style MERGE_MAIN fill:#E5E7EB,color:#1F2937,stroke:none
阶段五:功能测试 + 迭代
实现结束后,类似 plan 阶段,需要让 AI review 几轮实现的代码,然后让它自行修正。这个阶段不用太关注具体代码内容(那是下个阶段的事),这一步更多是让 AI 自己去修正一些潜在的严重的破坏性 bug。
代码侧的 review 结束后,还需要进行功能侧的 review。因为我主要做 Unity 开发,之前尝试过用开源的 Unity MCP 让 AI 通过 MCP 进行 agent 主导的功能测试,但效果不太理想,后来还是以人工测试为主。当然所谓”人工测试”也不完全是纯手动——将你最手动的那部分工作工具化还是很有必要的。
在功能测试过程中,你可能会发现实现与设计的偏差,或者单纯觉得实现和预想不太一样,想做一些微调。我的建议是:从文档开始,先修改文档,然后再重新走一遍流程,根据实际情况着重关注某个阶段或跳过一些阶段。
阶段六:人工 Review
这是最后的、也是第二耗时的阶段。这一步和传统 code review 差别不大,不过区别在于:你可以让 AI 划出 review 的重点,理清逻辑线条,并且和 AI 讨论后让它来改代码。
这是我前几天实际使用的一个 prompt,供参考:
对比当前分支和main分支,我准备review一下所有变动。请你给我一个review清单并且按照优先级排序。你可以开一个agent team去做,也可以开subagent来给我准备清单
注意
1. 如果你用git diff,将会发现很多变动,请你灵活处理。
2. 理解这些变动,然后给我一个人工review的清单
这里不得不提到一个比较激进的观点:在 vibe coding 中,任何人工介入对于整个流程来说都是一种”摩擦”,因此任何人工 review 都是不建议的。我个人从务实的角度来看,2026 年 3 月这个时间点,不进行任何人工 review 是行不通的。当下模型的能力边界还比较清晰,它无法独立实现一个可维护的、具有一定复杂度的系统。从可维护性的角度来说,人类仍然是不可或缺的一环。
有人可能会说,AI 写的代码只要 AI 自己能维护就好了。但根据我的开发经验,维护一个系统的复杂度不会低于从零开发一个系统,很可能只会更高。如果 AI 在当前阶段无法开发一个可维护的系统,那它同样也很难很好地维护一个系统。
小结
至此,整个工作流的循环已经比较清晰了。接下来的任务就是重复这六个阶段,直至对结果满意。
一般来说,我会在开 PR 之前额外让 agent 快速 plan 并实现一批单元测试。坦白说这一步我做得比较草率,目前没有太多经验可以分享,但我想说的是:近乎零成本的单元测试会让开发体验舒适很多。而且反正成本极低,哪天看这堆测试不顺眼,随时可以整个删掉重写,可以说是百利而无一害。
针对刚才的所有修改,设计测试,并且确保测试
1. 简洁,可维护
2. 只cover关键逻辑
3. 关注系统的交界点,而不是系统内部的细节实现
有不懂的可以问我
工作流二:原型主导
第二个工作流相对没那么结构化,也更加自然,可能大家每天都在做了——对于体量较小的、或者当前非常模糊的需求,完全可以跳过文档,用原型主导的开发代替文档主导的开发。
如果某个功能体量较小,完整走一遍文档驱动流程所产生的额外开销和空转时间可能比实际开发的投入还多。对于非常模糊的需求,写文档更是伪命题,不如先让 AI 做个勉强能用的东西,实际上手感受一下,理清需求了再迭代。
此外,这种方式对于存在预先共识的、非独创的系统效果非常好,因为这些系统的知识已经在模型训练过程中被学习了,你不需要费力地再解释一遍该怎么做。比如让 AI 实现一个类似马里奥的平台跳跃移动机制,直接让它做,一般也能做个八九不离十。所以一开始不需要把细节想得太清楚,原型做完之后自然就清楚了。有了第一版原型后,基于它直接往上迭代新功能即可。
当然,你一定会在某个时刻发现,系统的体量膨胀到你和 AI 仅通过对话已经无法轻松 debug 了。但一般到了那时,你对这个系统的功能也已经有了明确感知,完全可以让 AI 阅读代码,基于当前版本生成一份功能文档,然后切换到前面所说的文档优先方式重做一遍。这样就能成功地将一个模糊的 idea 转变为功能逻辑清晰、技术架构清晰的完整实现。
flowchart LR
IDEA["模糊想法"] --> PROTO["原型对话开发"]
PROTO --> CHECK{复杂度<br/>膨胀了?}
CHECK -->|否,继续迭代| PROTO
CHECK -->|是| GEN["AI 阅读代码<br/>生成功能文档"]
GEN --> DOC["切换到<br/>文档主导流程"]
style IDEA fill:#E5E7EB,color:#1F2937,stroke:none
style PROTO fill:#2563EB,color:#fff,stroke:none
style CHECK fill:#F59E0B,color:#fff,stroke:none
style GEN fill:#10B981,color:#fff,stroke:none
style DOC fill:#EF4444,color:#fff,stroke:none
文档的生命周期
在结束工作流部分之前,补充说明一下文档优先模式下文档的生命周期问题。
文档成型之后,它的生命周期完全取决于系统的性质——有些系统的文档需要你持续维护,有些则用完即弃。
第一种情况:持续维护。 这是我大部分时候的选择。文档不会用后即弃,而是需要在后续开发中不断维护。你需要像前 AI 时代维护代码一样花精力来维护文档:改功能时尽可能从文档改起,如果代码和文档出现分歧,需要及时统一。在 agent 的帮助下,这项工作可能没有想象中那么难。
第二种情况:用完即弃。 等实现充分测试完成之后,这篇文档就不再重要了,充分贯彻”代码本身即文档”的思想。尤其是现在有了 AI 作为中间层,理解代码的成本比前 AI 时代低了很多。
至于什么时候用哪种策略,我会套用一个简单的二维坐标轴分类法:
- X 轴:右侧是方便被自然语言描述的系统,左侧是不好被自然语言描述的系统。这里的”自然语言”包括形式化工具,比如有限状态机或具有明确定义的数学模型。
- Y 轴:上方是核心系统,下方是非核心系统。
quadrantChart
title 文档生命周期
x-axis "难以描述" --> "容易描述"
y-axis "非核心系统" --> "核心系统"
quadrant-1 "Q1: 持续维护"
quadrant-2 "Q2: 视情况而定"
quadrant-3 "Q4: 跳过文档"
quadrant-4 "Q3: 用完即弃"
系统在开发过程中会不断演进,重要性和可描述性也会发生变化,需要不定期地去评估。但对于位于第一象限(核心且易于描述)的系统,持续维护文档的 ROI 显然是最高的,对我来说几乎是必做的。其他象限的情况可以根据个人偏好决定。
第二部分:为什么我认为文档是核心
前面分享了具体工作流,接下来谈谈背后的思考:在 2026 年 3 月这个时间点,为什么我认为对于核心系统来说,持续花精力维护文档是必要的。
你的角色被迫升级了
曾经属于一线工程师(中低级别 IC)的很多职能,已经能被 agent 替代了,导致中低级一线工程师的职能自然向高级演化。以前那些一个人埋头写几个月项目的人,现在大部分编码工作 agent 都能代劳,你负责监管和把握方向就行。也就是说,”监督和把控方向”这个曾经属于高级工程师或经理的职责,现在落到了每个人身上。
block-beta
columns 2
block:BEFORE:1
columns 1
B_TITLE["传统开发"]
B1["你:写代码、调试、测试"]
B2["高级/经理:监督方向"]
end
block:AFTER:1
columns 1
A_TITLE["AI 编码时代"]
A1["Agent:写代码、调试、测试"]
A2["你:监督方向 + 维护文档"]
end
style B_TITLE fill:#E5E7EB,color:#1F2937,stroke:none
style B1 fill:#F9FAFB,color:#1F2937,stroke:#E5E7EB
style B2 fill:#F9FAFB,color:#9CA3AF,stroke:#E5E7EB
style A_TITLE fill:#60A5FA,color:#fff,stroke:none
style A1 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
style A2 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
但现阶段 agent 的自主性和长期记忆还无法比拟真正的人类,所以你仍然需要保持对项目一定深度的了解,才能让项目在正确的轨道上推进。这部分的认知负担虽然比不了亲手写代码,但相对于以前那些高级工程师对其负责项目的认知负担来说,依然不小。
你的带宽被迫扩大了
生产力的提高和转移,不可避免地导致你手头负责的项目规模或数量比以前大幅提升。这个数字对我来说,体感大约是 5 到 10 倍。
block-beta
columns 2
block:BEFORE:1
columns 1
B_TITLE["传统开发"]
B1["负责范围:1x"]
B2["亲手写每一行代码"]
B3["记住所有代码细节"]
end
block:AFTER:1
columns 1
A_TITLE["AI 编码时代"]
A1["负责范围:5~10x"]
A2["Agent 写代码,你把控方向"]
A3["文档 = 你的长期记忆"]
end
style B_TITLE fill:#E5E7EB,color:#1F2937,stroke:none
style B1 fill:#F9FAFB,color:#1F2937,stroke:#E5E7EB
style B2 fill:#F9FAFB,color:#1F2937,stroke:#E5E7EB
style B3 fill:#F9FAFB,color:#1F2937,stroke:#E5E7EB
style A_TITLE fill:#60A5FA,color:#fff,stroke:none
style A1 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
style A2 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
style A3 fill:#EFF6FF,color:#1E40AF,stroke:#BFDBFE
这时候再要求你保持对所有项目的代码细节、甚至技术架构的中长期记忆,对大多数人来说是不可能的。
文档成了你的”源代码”
因此,代码的上一层抽象形式——文档——就不可避免地成了你与所负责项目之间最重要的接口。
文档相对于代码,损失了大多数细节,但保留了项目的核心骨架。并且因为它是自然语言写的,阅读、记忆和修改的成本相对于代码(本质上是计算机的语言)来说,对人类要低得多。
更重要的是,在 agent 的帮助下,把文档转换成代码实现的成本已经大幅降低,并且在肉眼可见的未来还在迅速下降。自然语言与代码实现之间的边界,在以 agent 为翻译中间层的情况下,会越来越模糊。即使我们只把当前的 agent 视为一个不确定模型,高级语言编写的代码和自然语言的关系,也会逐渐朝着机器语言和高级语言的关系发展——最终工程师不再需要掌握高级语言本身,而可以只关注更抽象的技术架构和软件行为逻辑。
因此,在正在开启的 AI 编程时代里,编写和维护文档的重要性,约等于前 AI 时代编写和维护代码的重要性。
block-beta
columns 2
block:BEFORE:1
columns 1
A1["传统开发"]
A2["文档(可选,经常过时)"]
A3["高级语言 ← 你在这里工作"]
A4["机器语言"]
end
block:AFTER:1
columns 1
B1["AI 编码时代"]
B2["文档 / PRD ← 你在这里工作"]
B3["高级语言(Agent 负责翻译)"]
B4["机器语言"]
end
style A1 fill:none,stroke:none,color:#6B7280
style A2 fill:#F3F4F6,color:#1F2937,stroke:none
style A3 fill:#FDE68A,color:#92400E,stroke:none
style A4 fill:#E5E7EB,color:#374151,stroke:none
style B1 fill:none,stroke:none,color:#3B82F6
style B2 fill:#FDE68A,color:#92400E,stroke:none
style B3 fill:#E5E7EB,color:#374151,stroke:none
style B4 fill:#E5E7EB,color:#374151,stroke:none
当然,我相信 agent 的长期记忆和主动性这两块短板一旦被弥补,我们可能连主动维护文档也不太需要了,曾经一线工程师的职能可以被彻底交给 agent。但在那天到来之前,这是我目前找到的最好的方式。
第三部分:踩坑总结和建议
最后分享一些零散但实用的建议。
1. 计划先行,实现后行
数据分析领域有一句话叫”垃圾进,垃圾出”,这在 AI 编程领域同样适用。你给的信息越充分,AI 的产出就越好。就算再想偷懒,Claude Code 或 Codex 自带的 plan 功能也值得一试。
2. 让 agent 写测试,零成本带来的无限 ROI
我个人的体验是:写得不完美也没关系,但有和没有的差距相当大。
3. 固定流程 skill 化
不要自己动手,让 agent 把固定的手动流程脚本化、封装成 skill。比如修改完成后自动编译、跑测试、读日志等等,可以节约大量时间并大幅减少开发者上下文切换的开销。
4. 不要过度关注代码细节
如果你像前 AI 时代一样关注代码的每一处细节,大概率没有充分利用 AI 的能力。当然这不是说不看代码——代码是一定要看的——但应该关注代码的主干和架构,以及系统之间的交互点,并时刻留意这些部分的演进。在必要的时候要果断进行重构和迁移。
5. 保持工具的轻量化
除非你个人非常感兴趣,或者确实能给项目带来直接收益,否则不要在工具链上花太多时间。一月份的时候我尝试自己做 multi-agent orchestration 工具,花了很多钱但效果不显著;后来用了 OpenCode,感觉还不错,但性价比相比 Claude Code 和 Codex 实在太低。最终回归轻量化,只用 Claude Code 配合 Codex,产出依然很高。
关于这一点,我还有一个判断:如果你的精力有限,不要站在大模型公司这辆巨大的卡车前面给它铺路,让它们自己铺就好。否则大概率在你收回开发成本之前,就会被碾过。
目前我对 agent 工具短期发展方向的判断是无缝化。比如 /btw 这样的无缝交互、自动化的 worktree 管理、基于上下文的 feature 优先级排序等等,这些能力我认为到年底就不需要手动处理了。所以如果现在有人想做这个方向的工具,从投产比的角度来说,可能并不划算。
6. 关于团队场景
如开头所说,这套工作流主要是在单人开发的场景下验证的。不过我并不认为它不适用于更大的团队。随着 AI 让每个工程师能 own 的边界越来越大,把项目拆成正交模块相比以前应该更容易。只要拆分做得好——边界清晰、共享状态少——每个人完全可以在自己的模块内独立跑这套流程。团队协调的重心也会从”怎么一起写代码”转变为”怎么定义模块间的接口”,这是一个更可控的问题。但我目前还没有在更大规模的团队中实践过,等有了经验再分享。
总结
最后做一个关于工作流的小结:
flowchart TD
START([新功能需求]) --> DECIDE{体量大且<br/>方向明确?}
DECIDE -->|是| DOC[文档主导<br/>六阶段流水线]:::human
DOC --> SAT[满意 > 开PR]:::done
SAT --> LIFE{核心且<br/>容易描述?}
LIFE -->|是| MAINTAIN[持续维护文档]:::done
LIFE -->|否| DISCARD[用完即弃]:::gray
DECIDE -->|否| PROTO[原型主导<br/>对话式开发]:::ai
PROTO --> COMP{复杂度<br/>膨胀了?}
COMP -->|否| PROTO
COMP -->|是| GEN[AI阅读代码<br/>生成功能文档]:::ai
GEN -->|切换到<br/>文档主导| DOC
classDef human fill:#EF4444,color:#fff,stroke:none
classDef ai fill:#2563EB,color:#fff,stroke:none
classDef done fill:#10B981,color:#fff,stroke:none
classDef gray fill:#6B7280,color:#fff,stroke:none
- 对于大规模的、定义明确的 feature,以文档为核心主导开发。
- 对于重要且容易被描述的 feature,持续维护文档。
- 对于其他 feature,见机行事。
- 对于小 feature 或定义不明确的 feature,以原型开发为核心。当它演化为定义明确的大 feature 时,回到前一套逻辑进行重构。
整篇文章是站在一线工程师的角度写的,但我相信 agent 给每个角色都带来了工作方式上的巨变,这种巨变必然会导致组织关系的变化。希望大家都能抓住这个机会,做一些曾经敢想不敢做的事情。